在這篇文章中,我們將要討論的內容是:
- 什麼是「圖像增強」?其重要性何在?
- 如何使用Keras實現基本的「圖像增強」?
- 什麼是「直方圖均衡」?如何發揮其作用?
- 直方圖均衡法——修改keras.preprocessing image.py文件的方式之一
- 什麼是「圖像增強」?其重要性何在?
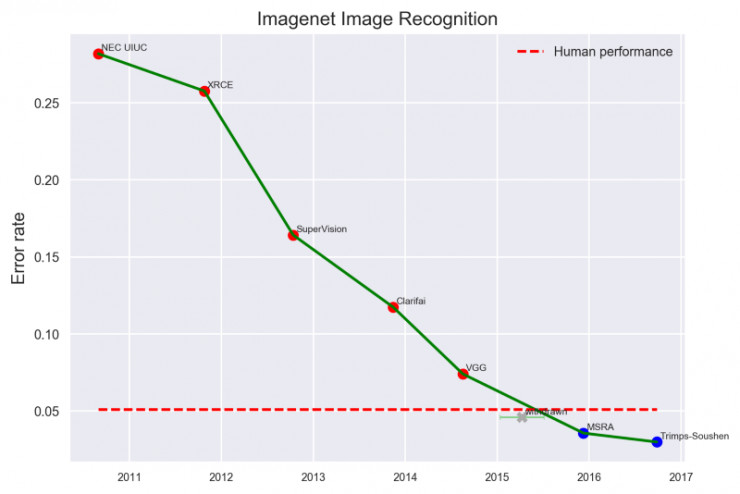
深度神經網絡,尤其是卷積神經網絡(CNN),非常擅長於圖像分類。事實證明,最先進的卷積神經網絡在圖像識別方面的性能已經超過了人類水平。 然而,正如我們在楊建先生的「Hot Dog, Not Hot Dog」App(在一個叫做「Silicon Valley」的熱門電視節目中的食物識別App)中瞭解到的,將圖像收集起來作爲訓練數據使用,是一項非常昂貴且耗時的工作。
如果你對「Silicon Valley」這個電視節目不太熟悉,請注意以下視頻中的語言是NSFW:
我們通過擴充圖像數據的方式,從一個已有的數據庫中生成更多新的訓練圖像,以降低收集訓練圖像的成本。「圖像擴充」其實就是從已有的訓練數據集中取出一些圖像,然後根據這些圖像創建出許多修改版本的圖像。這樣做不僅能夠獲得更多的訓練數據,還能讓我們的分類器應對光照和色彩更加複雜的環境,從而使我們的分類器功能越來越強大。以下是來自imgaug的不同的圖像擴充例子:

https://github.com/aleju/imgaug
圖像預處理的方法有很多。在本文中,我們將討論一些常見的、富有創意的方法,這些方法也是Keras深度學習庫爲擴充圖像數據所提供的。之後我們將討論如何轉換keras預處理圖像文件,以啓用直方圖均衡法。我們將使用Keras附帶的cifar10數據集,但是爲了使任務小到能夠順利在CPU上執行,我們將只會使用其中的貓和狗的圖像。
首先,我們需要加載cifar10數據集並格式化其中的圖像,爲卷積神經網絡做好準備。我們還要檢查一下部分圖像,確保數據已經完成了正確的加載。
from __future__ import print_function
import keras
from keras.datasets import cifar10
from keras import backend as K
import matplotlib
from matplotlib import pyplot as plt
import numpy as np#Input image dimensions
img_rows, img_cols = 32, 32#The data, shuffled and split between train and test sets
(x_train, y_train), (x_test, y_test) = cifar10.load_data()#Only look at cats [=3] and dogs [=5]
train_picks = np.ravel(np.logical_or(y_train==3,y_train==5))
test_picks = np.ravel(np.logical_or(y_test==3,y_test==5))y_train = np.array(y_train[train_picks]==5,dtype=int)
y_test = np.array(y_test[test_picks]==5,dtype=int)x_train = x_train[train_picks]
x_test = x_test[test_picks]if K.image_data_format() == 'channels_first':
x_train = x_train.reshape(x_train.shape[0], 3, img_rows, img_cols)
x_test = x_test.reshape(x_test.shape[0], 3, img_rows, img_cols)
input_shape = (3, img_rows, img_cols)
else:
x_train = x_train.reshape(x_train.shape[0], img_rows, img_cols, 3)
x_test = x_test.reshape(x_test.shape[0], img_rows, img_cols, 3)
input_shape = (img_rows, img_cols, 3)x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_test /= 255print('x_train shape:', x_train.shape)
print(x_train.shape[0], 'train samples')
print(x_test.shape[0], 'test samples')#Convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(np.ravel(y_train), num_classes)
y_test = keras.utils.to_categorical(np.ravel(y_test), num_classes)#Look at the first 9 images from the dataset
images = range(0,9)
for i in images:
plt.subplot(330 + 1 + i)
plt.imshow(x_train, cmap=pyplot.get_cmap('gray'))
#Show the plot
plt.show()

Cifar10數據集中的圖像都是32x 32像素大小的,因此放大來看,它們都呈現出顆粒狀。但是對卷積神經網絡來說,它看到的不是顆粒,而是數據。
- 使用ImageDataGenerator函數創建一個圖像生成器
用Keras進行圖像數據的擴充是非常簡單的,在這裏,我們應該感謝Jason Brownlee,因爲是他給我們提供了一個非常全面、到位的Keras圖像擴充教程。圖象擴充的過程如下:首先,我們需要使用 ImageDataGenerator()函數來創建一個圖像生成器,並且輸入一系列描述圖像更改行爲的參數;之後,我們將在這個圖像生成器中執行fit()函數,它將會一批一批地對圖像進行更改。在默認情況下,圖像的更改是任意的,所以並不是所有圖像每次都會被更改。你還可以用 keras.preprocessing 函數將擴充的圖像導出到一個文件夾,以便建立一個更龐大的擴充圖像數據集。
在本文中,我們將看一些更直觀、有趣的擴充圖像。你可以在Keras文件中查看所有的ImageDataGenerator參數,以及keras.preprocessing中的其他方法。
# Rotate images by 90 degrees
datagen = ImageDataGenerator(rotation_range=90)# fit parameters from data
datagen.fit(x_train)# Configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(x_train, y_train, batch_size=9):
# Show 9 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(X_batch.reshape(img_rows, img_cols, 3))
# show the plot
pyplot.show()
break

# Flip images vertically
datagen = ImageDataGenerator(vertical_flip=True)# fit parameters from data
datagen.fit(x_train)# Configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(x_train, y_train, batch_size=9):
# Show 9 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(X_batch.reshape(img_rows, img_cols, 3))
# show the plot
pyplot.show()
break

水平翻轉圖片同樣是爲分類器生成更多數據的一種經典方式。這麼做非常簡單,但是我在這裏省略了代碼和圖像,是因爲我們在沒有看到原始圖像的情況下,無法判斷一張貓狗的圖像是否被水平翻轉了。
# Shift images vertically or horizontally
# Fill missing pixels with the color of the nearest pixel
datagen = ImageDataGenerator(width_shift_range=.2,
height_shift_range=.2,
fill_mode='nearest')# fit parameters from data
datagen.fit(x_train)# Configure batch size and retrieve one batch of images
for X_batch, y_batch in datagen.flow(x_train, y_train, batch_size=9):
# Show 9 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(X_batch.reshape(img_rows, img_cols, 3))
# show the plot
pyplot.show()

break直方圖均衡法 直方圖均衡,即取一張低對比度圖像,並提高圖像中最亮和最暗部分之間的對比度,以找出陰影的細微差別,並創建一個更高對比度的圖像。使用這個方法所產生的結果相當驚人,尤其是針對那些灰度圖像。以下是一些例子:

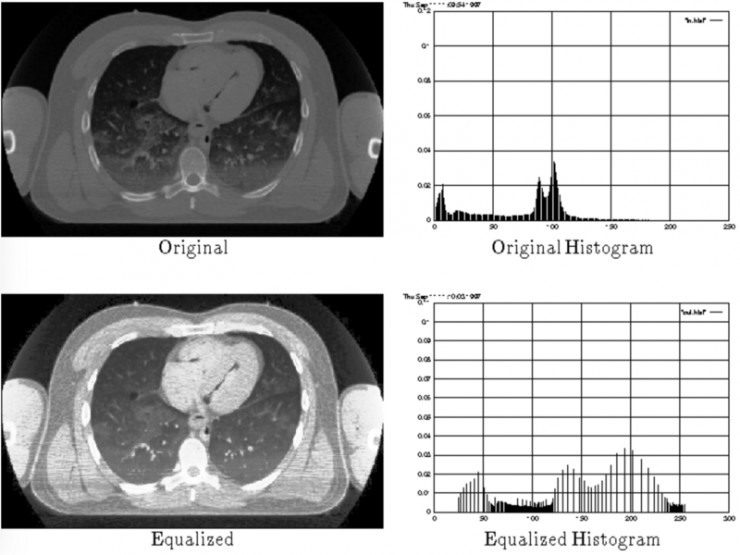
在本文中,我們將討論三種用於提高圖像對比度的圖像擴充方法。這些方法有時也被稱作「直方圖拉伸」,因爲它們會使用像素強度的分佈,並擴展這些分佈以適應更大範圍的值,從而提高圖像中最亮和最暗部分之間的對比度。
直方圖均衡法通過檢測圖像的像素強度分佈,並繪製出一個像素強度直方圖,從而提高圖像的對比度。之後,這個直方圖的分佈會被進行分析,如果分析結果顯示還有未被利用的像素亮度範圍,那麼這個直方圖就會被「擴展」,以涵蓋這些未被利用的範圍。然後直方圖將被「投射」到圖像上,以提高圖像的整體對比度。
「對比度擴展」的過程首先是分析圖像中的像素強度分佈,然後重新調節圖像,使圖像能夠涵蓋在2%至98%之間的所有像素強度。
在直方圖計算方面,「自適應均衡」與常規的直方圖均衡有很大的區別。常規的直方圖均衡法中,每個被計算的直方圖都與圖像中的一個部分相對應;但是,它有着在非正常圖像部分過度擴充噪聲的趨勢。
下面的代碼來自於sci-kit圖像庫的文件。爲了使這些代碼能夠在我們cifar10數據集的第一張圖像上執行以上三種圖像擴充,我們對代碼進行了轉換和修改。首先,我們將輸入sic-kit圖像庫中的必要單元,然後對sci-kit圖像文件中的代碼進行修改和調整,以便查看數據集第一張圖片的擴充圖像集。
# Import skimage modules
from skimage import data, img_as_float
from skimage import exposure# Lets try augmenting a cifar10 image using these techniques
from skimage import data, img_as_float
from skimage import exposure# Load an example image from cifar10 dataset
img = images[0]# Set font size for images
matplotlib.rcParams['font.size'] = 8# Contrast stretching
p2, p98 = np.percentile(img, (2, 98))
img_rescale = exposure.rescale_intensity(img, in_range=(p2, p98))# Histogram Equalization
img_eq = exposure.equalize_hist(img)# Adaptive Equalization
img_adapteq = exposure.equalize_adapthist(img, clip_limit=0.03)#### Everything below here is just to create the plot/graphs ####
# Display results
fig = plt.figure(figsize=(8, 5))
axes = np.zeros((2, 4), dtype=np.object)
axes[0, 0] = fig.add_subplot(2, 4, 1)
for i in range(1, 4):
axes[0, i] = fig.add_subplot(2, 4, 1+i, sharex=axes[0,0], sharey=axes[0,0])
for i in range(0, 4):
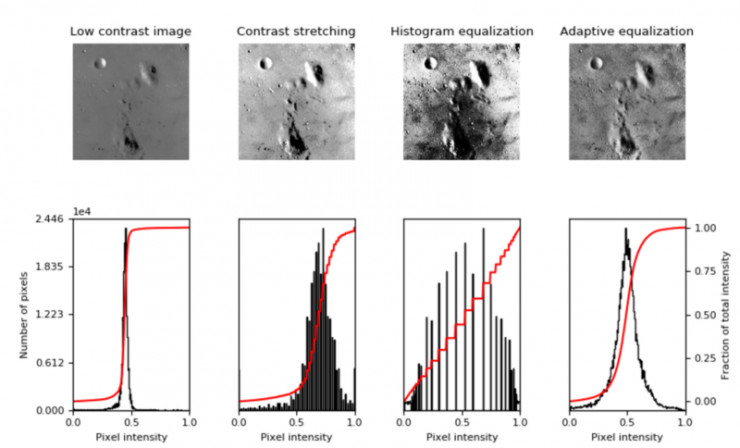
axes[1, i] = fig.add_subplot(2, 4, 5+i)ax_img, ax_hist, ax_cdf = plot_img_and_hist(img, axes[:, 0])
ax_img.set_title('Low contrast image')y_min, y_max = ax_hist.get_ylim()
ax_hist.set_ylabel('Number of pixels')
ax_hist.set_yticks(np.linspace(0, y_max, 5))ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_rescale, axes[:, 1])
ax_img.set_title('Contrast stretching')ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_eq, axes[:, 2])
ax_img.set_title('Histogram equalization')ax_img, ax_hist, ax_cdf = plot_img_and_hist(img_adapteq, axes[:, 3])
ax_img.set_title('Adaptive equalization')ax_cdf.set_ylabel('Fraction of total intensity')
ax_cdf.set_yticks(np.linspace(0, 1, 5))# prevent overlap of y-axis labels
fig.tight_layout()
plt.show()
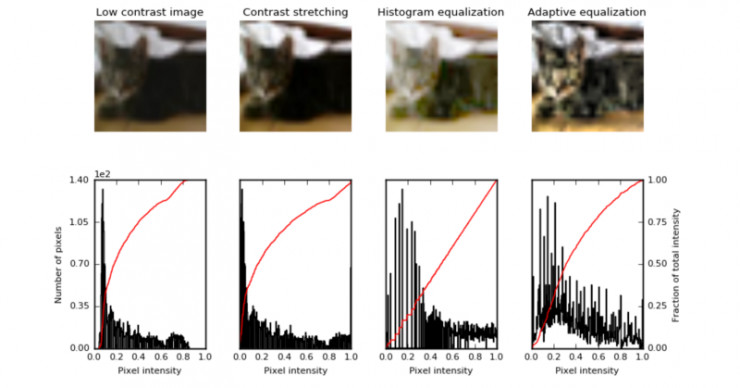
Here are the modified images of a low contrast cat from the cifar10 dataset. As you can see, the results are not as striking as they might be with a low contrast grayscale image, but still help improve the quality of the images.
下面這張圖是一張修改後的圖像,是由cifar10數據集中的一張對比度較低的貓咪圖片修改得到的。正如你所看到的,最後修改的圖像成果可能並不像在低對比度灰度圖像中得到的圖像成果那麼令人驚豔,但總的來說圖像的畫質還是得到了提高。
- 修改Keras.preprocessing以啓用「直方圖均衡法」
現在,我們已經成功地修改了cifar10數據集中的一張圖像,我們接下來將要討論如何調整或改變keras.preprocessing圖像文件,從而執行這些不同的直方圖修改方法,就像我們利用ImageDataGenerator()函數進行keras圖像擴充一樣。以下是我們將採取的幾個步驟:
- 步驟概述
- 找出keras.preprocessing image py文件
- 把image py文件複製到你的文件或者筆記本上。
- 給每個均衡方法添加一個屬性到ImageDataGenerator()init函數中。
- 把「IF」的表達語句添加到隨即轉換的方法中,這樣,我們在使用datagenfit()函數的時候,圖像擴充就會被執行。
對keras.preprocessing的圖像py文件進行修改和調整的最簡單的方式之一就是將文件中的內容複製、粘貼到我們的代碼中。這麼做的好處是省略了我們下一個輸入文件內容的步驟。你可以點擊此處查看github上的圖像文件。但是,爲了確保你拿到的文件是之前輸入的文件的相同版本,你最好取你的機器上已有的圖像文件。
運行print(keras._file_)將會打印出你機器上的keras庫的路徑,其路徑(針對IMac用戶)大致如下:
/usr/local/lib/python3.5/dist-packages/keras/__init__.pyc
這給我們提供了本機機器上的路徑,沿着路徑導航,然後進入preprocessing文件夾;在preprocessing文件夾中你就會看到圖像py文件,你可以將其中的內容複製到你的代碼中。這個文件有點長,但對於初學者來說,這應該是最簡單的方法了。
你可以在圖片頂部添加一行註釋:from..import backend as K
到這裏,你還需要再次檢查,以確保你輸入的是必須的scikit-image單元,這樣複製的image.py才能識別出。
from skimage import data, img_as_float
from skimage import exposure
現在,我們需要給ImageDataGenerator類的方法添加六行代碼,這樣它就有三個屬性來表示我們將要添加的圖像擴充類型。下面的代碼是從我現在的image.py中複製得來的:
def __init__(self,
contrast_stretching=False, #####
histogram_equalization=False,#####
adaptive_equalization=False, #####
featurewise_center=False,
samplewise_center=False,
featurewise_std_normalization=False,
samplewise_std_normalization=False,
zca_whitening=False,
rotation_range=0.,
width_shift_range=0.,
height_shift_range=0.,
shear_range=0.,
zoom_range=0.,
channel_shift_range=0.,
fill_mode=’nearest’,
cval=0.,
horizontal_flip=False,
vertical_flip=False,
rescale=None,
preprocessing_function=None,
data_format=None):
if data_format is None:
data_format = K.image_data_format()
self.counter = 0
self.contrast_stretching = contrast_stretching, #####
self.adaptive_equalization = adaptive_equalization #####
self.histogram_equalization = histogram_equalization #####
self.featurewise_center = featurewise_center
self.samplewise_center = samplewise_center
self.featurewise_std_normalization = featurewise_std_normalization
self.samplewise_std_normalization = samplewise_std_normalization
self.zca_whitening = zca_whitening
self.rotation_range = rotation_range
self.width_shift_range = width_shift_range
self.height_shift_range = height_shift_range
self.shear_range = shear_range
self.zoom_range = zoom_range
self.channel_shift_range = channel_shift_range
self.fill_mode = fill_mode
self.cval = cval
self.horizontal_flip = horizontal_flip
self.vertical_flip = vertical_flip
self.rescale = rescale
self.preprocessing_function = preprocessing_function
下面的random_transform()函數呼應我們之前傳輸至ImageDataGenerator函數的參數。如果我們把「對比度擴展」、「自適應均衡」或「直方圖均衡」的參數設置爲「True」,那麼當我們調用ImageDataGenerator函數的時候,random_transform()函數就會執行所需的圖像擴充。
def random_transform(self, x):
img_row_axis = self.row_axis - 1
img_col_axis = self.col_axis - 1
img_channel_axis = self.channel_axis - 1# use composition of homographies
# to generate final transform that needs to be applied
if self.rotation_range:
theta = np.pi / 180 * np.random.uniform(-self.rotation_range, self.rotation_range)
else:
theta = 0 if self.height_shift_range:
tx = np.random.uniform(-self.height_shift_range, self.height_shift_range) * x.shape[img_row_axis]
else:
tx = 0 if self.width_shift_range:
ty = np.random.uniform(-self.width_shift_range, self.width_shift_range) * x.shape[img_col_axis]
else:
ty = 0 if self.shear_range:
shear = np.random.uniform(-self.shear_range, self.shear_range)
else:
shear = 0 if self.zoom_range[0] == 1 and self.zoom_range[1] == 1:
zx, zy = 1, 1
else:
zx, zy = np.random.uniform(self.zoom_range[0], self.zoom_range[1], 2)transform_matrix = None
if theta != 0:
rotation_matrix = np.array([[np.cos(theta), -np.sin(theta), 0],
[np.sin(theta), np.cos(theta), 0],
[0, 0, 1]])
transform_matrix = rotation_matrix if tx != 0 or ty != 0:
shift_matrix = np.array([[1, 0, tx],
[0, 1, ty],
[0, 0, 1]])
transform_matrix = shift_matrix if transform_matrix is None else np.dot(transform_matrix, shift_matrix) if shear != 0:
shear_matrix = np.array([[1, -np.sin(shear), 0],
[0, np.cos(shear), 0],
[0, 0, 1]])
transform_matrix = shear_matrix if transform_matrix is None else np.dot(transform_matrix, shear_matrix) if zx != 1 or zy != 1:
zoom_matrix = np.array([[zx, 0, 0],
[0, zy, 0],
[0, 0, 1]])
transform_matrix = zoom_matrix if transform_matrix is None else np.dot(transform_matrix, zoom_matrix) if transform_matrix is not None:
h, w = x.shape[img_row_axis], x.shape[img_col_axis]
transform_matrix = transform_matrix_offset_center(transform_matrix, h, w)
x = apply_transform(x, transform_matrix, img_channel_axis,
fill_mode=self.fill_mode, cval=self.cval) if self.channel_shift_range != 0:
x = random_channel_shift(x, self.channel_shift_range, img_channel_axis) if self.horizontal_flip:
if np.random.random() < 0.5:
x = flip_axis(x, img_col_axis) if self.vertical_flip:
if np.random.random() < 0.5:
x = flip_axis(x, img_row_axis)
if self.contrast_stretching: #####
if np.random.random() < 0.5: #####
p2, p98 = np.percentile(x, (2, 98)) #####
x = exposure.rescale_intensity(x, in_range=(p2, p98)) #####
if self.adaptive_equalization: #####
if np.random.random() < 0.5: #####
x = exposure.equalize_adapthist(x, clip_limit=0.03) #####
if self.histogram_equalization: #####
if np.random.random() < 0.5: #####
x = exposure.equalize_hist(x) #####
return x
現在,所有必備的代碼都已經準備就緒了,那麼我們就可以調用ImageDataGenerator()函數執行直方圖修改的方法了。當我們將所有的參數設置爲True後,部分圖像就會變成這樣:
# Initialize Generator
datagen = ImageDataGenerator(contrast_stretching=True, adaptive_equalization=True, histogram_equalization=True)# fit parameters from data
datagen.fit(x_train)# Configure batch size and retrieve one batch of images
for x_batch, y_batch in datagen.flow(x_train, y_train, batch_size=9):
# Show the first 9 images
for i in range(0, 9):
pyplot.subplot(330 + 1 + i)
pyplot.imshow(x_batch.reshape(img_rows, img_cols, 3))
# show the plot
pyplot.show()
break

我不推薦在任何給定的數據集中將一個以上的參數設置爲True,你需要確保你的數據集實驗有助於你提高分類器的準確性。對於彩色圖像,我發現「對比度擴展」的成效優於「直方圖修改」或「自適應均衡」的成效。
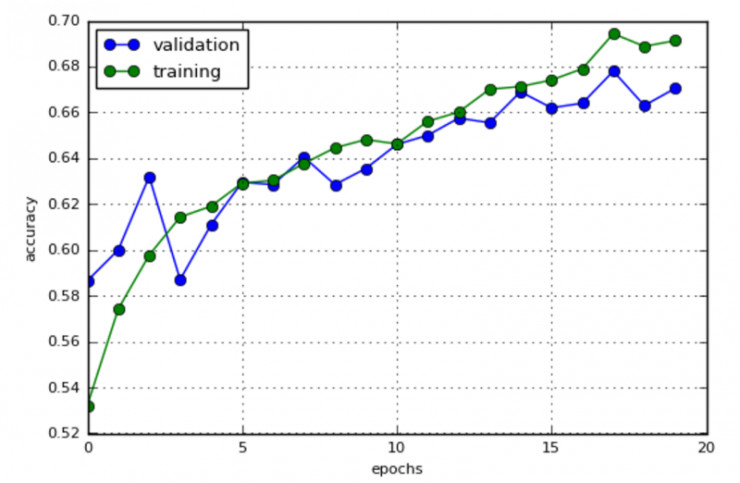
最後一步,訓練我們的卷積神經網絡,並使用 model.fit_generator() 函數驗證這個模型,從而實現在擴充圖像上的神經網絡的訓練和驗證。
from keras.models import Sequential
from keras.layers import Dense, Dropout, Flatten
from keras.layers import Conv2D, MaxPooling2Dbatch_size = 64
num_classes = 2
epochs = 10model = Sequential()
model.add(Conv2D(4, kernel_size=(3, 3),activation='relu',input_shape=input_shape))
model.add(Conv2D(8, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(16, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(2, activation='softmax'))
model.compile(loss=keras.losses.categorical_crossentropy,
optimizer=keras.optimizers.Adadelta(),
metrics=['accuracy'])datagen.fit(x_train)
history = model.fit_generator(datagen.flow(x_train, y_train, batch_size=batch_size),
steps_per_epoch=x_train.shape[0] // batch_size,
epochs=20,
validation_data=(x_test, y_test))
文章來源:雷鋒網
|

 發表於 17-8-27 19:47
發表於 17-8-27 19:47
 提升卡
提升卡 置頂卡
置頂卡 沉默卡
沉默卡 變色卡
變色卡 千斤頂
千斤頂 顯身卡
顯身卡